
Redis

Redis
pfaRedis面试
目录
Redis 核心原理
什么是 Redis
Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,可用作数据库、缓存和消息中间件。它支持多种数据结构,包括字符串、哈希、列表、集合、有序集合等,并提供了丰富的功能如事务、持久化、Lua 脚本、发布订阅、集群等。
Redis 为什么快
- 纯内存操作:数据存储在内存中,读写速度非常快
- 单线程模型:避免了多线程的上下文切换和锁竞争
- 非阻塞 I/O:使用 I/O 多路复用(epoll/kqueue)处理并发连接
- 高效的数据结构:底层实现经过优化,如 SDS、跳表等
数据结构底层实现
| 数据类型 | 底层编码 | 说明 |
|---|---|---|
| String | int、embstr、raw | 整数用 int,短字符串用 embstr,长字符串用 raw |
| List | ziplist、linkedlist、quicklist | 3.2+ 默认使用 quicklist |
| Hash | ziplist、hashtable | 元素少且值小时用 ziplist,否则用 hashtable |
| Set | intset、hashtable | 整数且元素少时用 intset,否则用 hashtable |
| Sorted Set | ziplist、skiplist | 元素少时用 ziplist,否则用 skiplist+dict |
持久化机制
RDB(Redis Database)
- 原理:在指定时间间隔内,将内存中的数据快照写入磁盘
- 优点:文件紧凑、恢复快、适合备份和灾难恢复
- 缺点:可能丢失最后一次快照后的数据
1 | save 900 1 # 900秒内至少1个键改变 |
AOF(Append Only File)
- 原理:以日志形式记录每个写操作,追加到文件末尾
- 优点:数据更安全,可读性好
- 缺点:文件体积大,恢复速度相对较慢
1 | appendonly yes # 开启 AOF |
混合持久化(4.0+)
- 结合 RDB 和 AOF 优点:前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据
过期键删除策略
- 定时删除:为每个过期键创建定时器,到期立即删除(内存友好,CPU 不友好)
- 惰性删除:访问键时才检查是否过期,过期则删除(CPU 友好,内存不友好)
- 定期删除:每隔一段时间抽取一些键检查并删除过期键(折中方案)
Redis 实际使用惰性删除 + 定期删除组合策略。
内存淘汰策略
当内存使用达到 maxmemory 限制时,Redis 会执行数据淘汰策略:
| 策略 | 说明 |
|---|---|
| noeviction | 不淘汰,返回错误 |
| allkeys-lru | 从所有键中淘汰最近最少使用 |
| volatile-lru | 从设置了 TTL 的键中淘汰最近最少使用 |
| allkeys-lfu | 从所有键中淘汰最不经常使用(4.0+) |
| volatile-lfu | 从设置了 TTL 的键中淘汰最不经常使用(4.0+) |
| allkeys-random | 从所有键中随机淘汰 |
| volatile-random | 从设置了 TTL 的键中随机淘汰 |
| volatile-ttl | 淘汰即将过期的键 |
集群方案
主从复制
1 | +----+ |
- 一个 Master 可以有多个 Slave
- 数据单向复制:Master → Slave
- 支持级联复制:Slave 可以作为其他 Slave 的 Master
Sentinel 哨兵
- 监控主从节点健康状态
- 自动故障转移:Master 故障时自动提升 Slave 为 Master
- 配置中心:客户端通过 Sentinel 获取 Master 地址
Cluster 集群(3.0+)
- 数据分片:16384 个哈希槽,每个节点负责一部分槽
- 去中心化:无中心节点,客户端可连接任意节点
- 高可用:支持主从复制和故障转移
数据类型
1 | String: 字符串 |
docker-redis
1 | 1. config get requirepass 查看redis密码 |
1.3springboot集成redis
1 | # 引入maven依赖 |
缓存穿透、缓存击穿、缓存雪崩
一、缓存穿透
描述
指访问一个缓存和数据库中都不存在的key,由于这个key在缓存中不存在,则会到数据库中查询,数据库中也不存在该key,无法将数据添加到缓存中,所以每次都会访问数据库导致数据库压力增大。解决方法
将空key添加到缓存中。
使用布隆过滤器过滤空key。
一般对于这种访问可能由于遭到攻击引起,可以对请求进行身份鉴权、数据合法行校验等。
二、缓存击穿
描述
指大量请求访问缓存中的一个key时,该key过期了,导致这些请求都去直接访问数据库,短时间大量的请求可能会将数据库击垮。解决方法
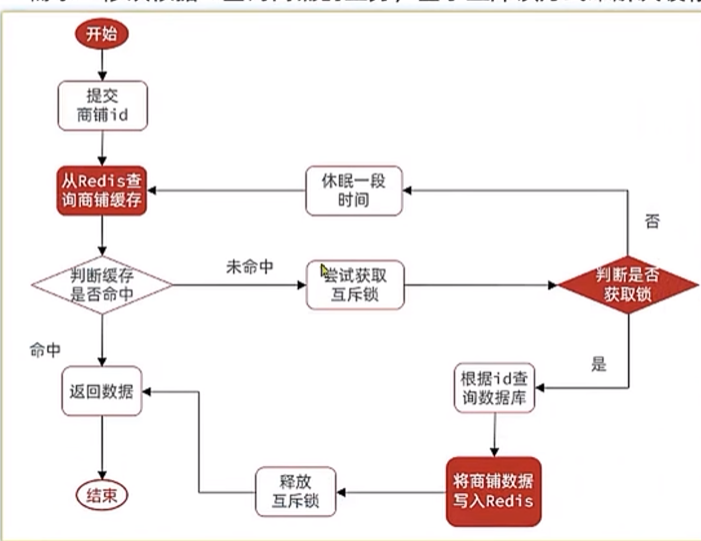
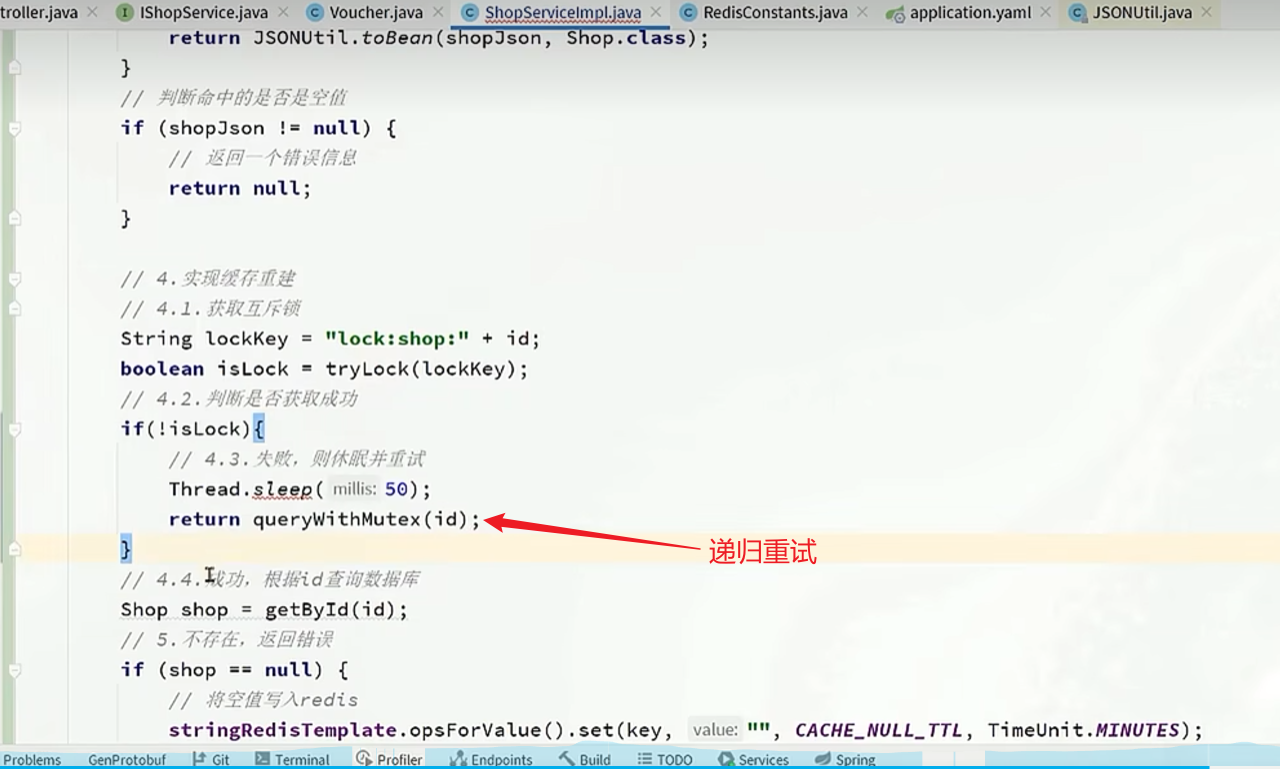
- 添加互斥锁或分布式锁,让一个线程去访问数据库,将数据添加到缓存中后,其他线程直接从缓存中获取。(通常方案-p44)
添加锁 setnx lock 1 100ttl(防止死锁)
删除锁delete lock
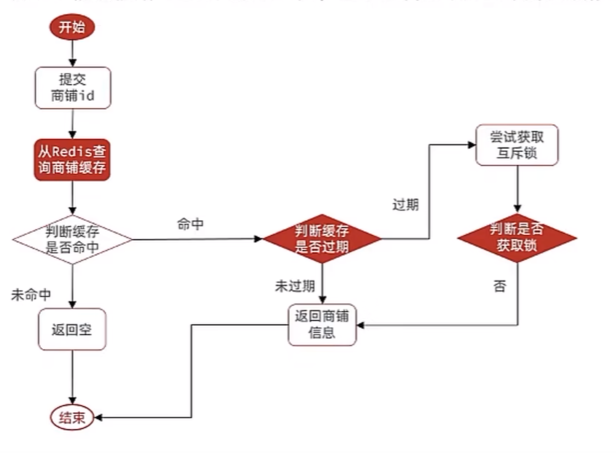
热点数据key不过期,定时更新缓存,但如果更新出问题会导致缓存中的数据一直为旧数据。(根据业务场景)
逻辑过期:子线程重建缓存
三、缓存雪崩
描述
指在系统运行过程中,缓存服务宕机或大量的key值同时过期,导致所有请求都直接访问数据库导致数据库压力增大。解决方法
将key的过期时间打散,避免大量key同时过期。
对缓存服务做高可用处理。
加互斥锁,同一key值只允许一个线程去访问数据库,其余线程等待写入后直接从缓存中获取。
一致性
redis内存回收
ttl过期时间
主动更新
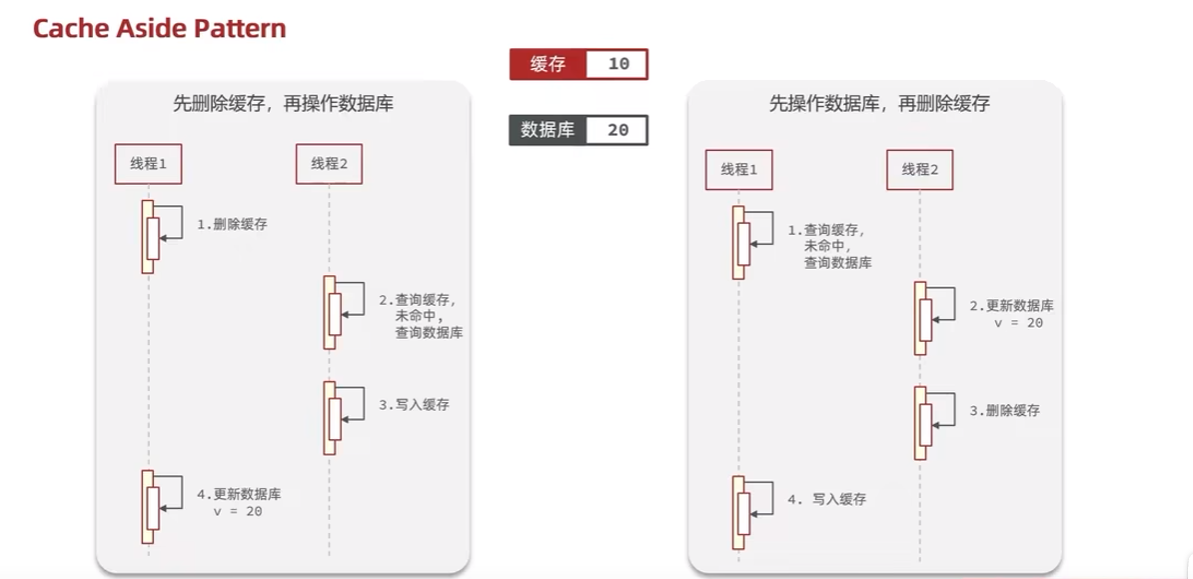
- 先删除缓存,在更新数据库
- 先更新数据库在删除缓存(一般方案,操作内存快,操作数据库慢)
redisssion
- 可重入
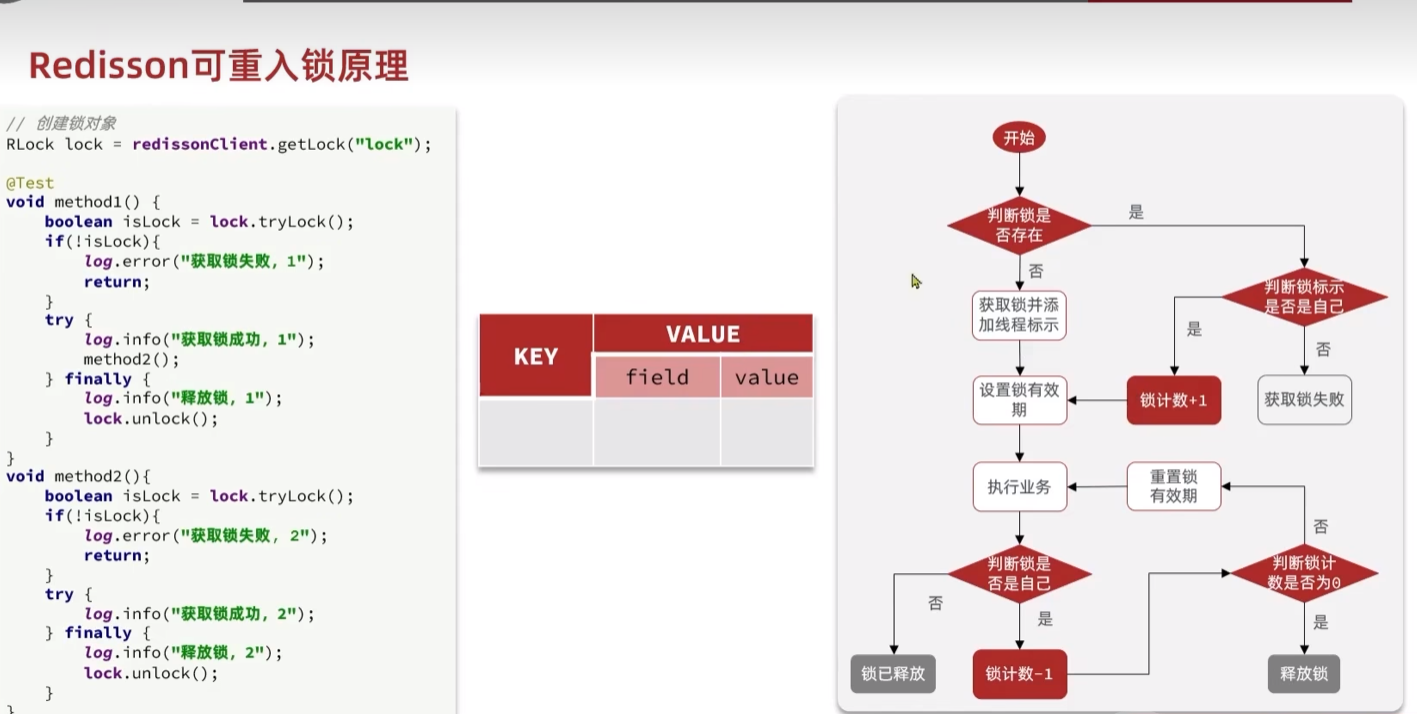
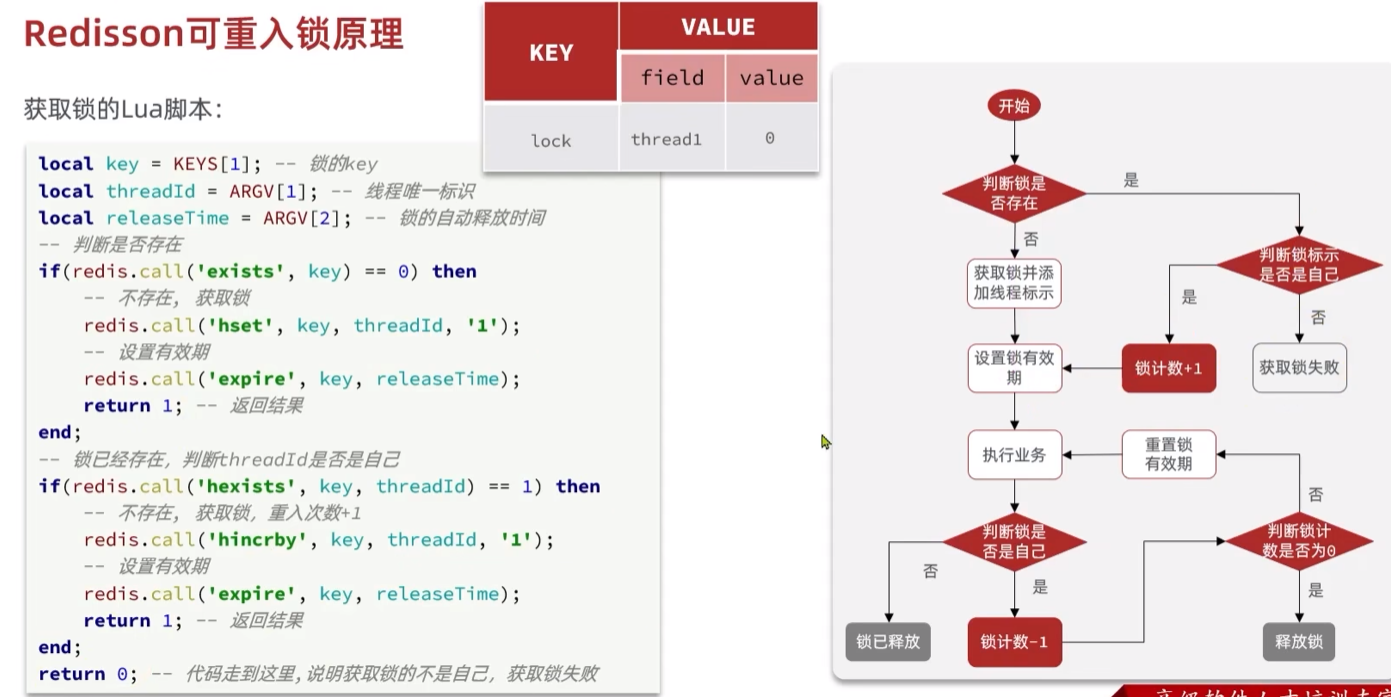
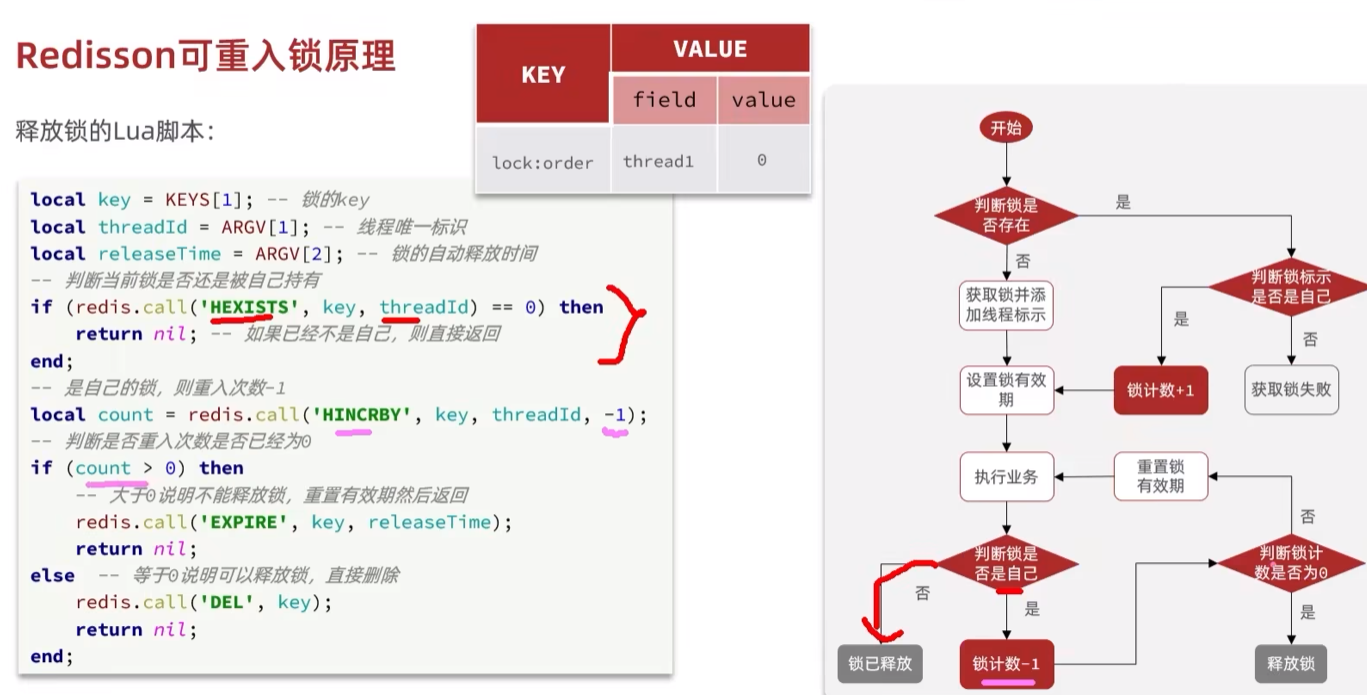
1 | //redisson 可重入 可重试锁 |
业务未执行完ttl过期问题
redisson锁
可重入:redis的hash结构
可重试:waitTime 、leaseTiem(TTl)、锁释放消息订阅
业务超时锁过期问题:判断leasTiem是否等于-1启用watchdog(看门狗)
分布式集群一致性问题:不分主库和从库,multLock多把锁结合成一把锁
秒杀业务解耦
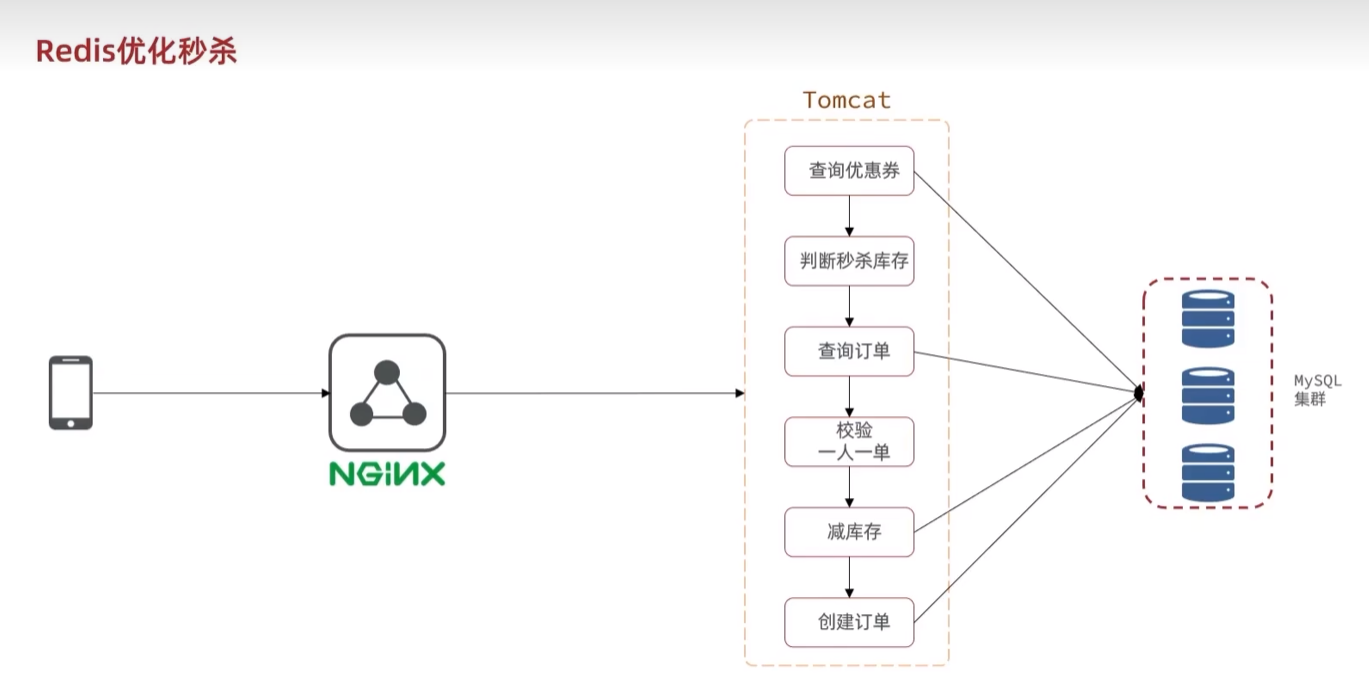
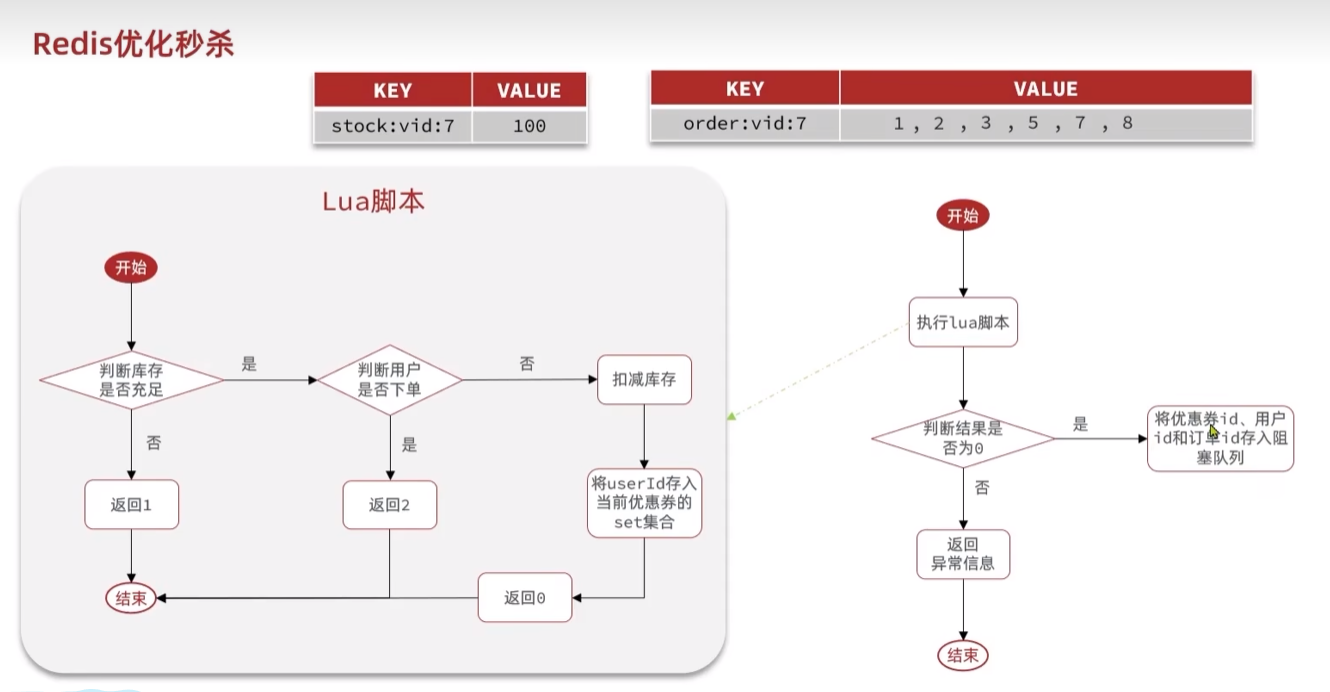
生成订单
1 | -- 判断是否下单----> |
消费订单
- redis:扣减库存,使用阻塞队列指令LRPUSH、LRPOP

订阅型消费
SUBSCRIBLE、PUBLISH
stream实现消息队列
- XADD: XADD S! * k1 v1
- XREDE:XREAD COUNT 0 [block 0] SREAMS S1 0(哪个singal) $(最新)
- XLEN
缺点:有消息遗漏,由于是阻塞的消息队列,当拿到最新的消息后,中间有连续几条新校西,只会拿到最后的消息
stream消息消费组
- XGROUP

常见面试问题
1. Redis 和 Memcached 的区别
| 对比项 | Redis | Memcached |
|---|---|---|
| 数据类型 | 5种基本类型 + 多种高级结构 | 仅 String |
| 持久化 | 支持 RDB 和 AOF | 不支持 |
| 内存淘汰 | 8种策略 | LRU |
| 分布式 | 原生 Cluster 或 Sentinel | 需要客户端分片 |
| 单value大小 | 最大 512MB | 最大 1MB |
| 线程模型 | 单线程(6.0+ 多线程 I/O) | 多线程 |
2. 如何保证缓存与数据库的一致性
方案一:先更新数据库,再删除缓存(推荐)
1 | // 1. 更新数据库 |
方案二:先删除缓存,再更新数据库(可能有并发问题)
1 | // 1. 删除缓存 |
方案三:延迟双删
1 | // 1. 删除缓存 |
方案四:基于 Binlog 的异步更新(Canal + MQ)
3. Redis 单线程为什么还这么快
- 纯内存操作:数据都在内存里,读写速度快
- 单线程避免了上下文切换和锁竞争
- I/O 多路复用模型:使用 epoll/kqueue 处理并发连接
- 高效的数据结构:SDS、跳表、压缩列表等
注意:Redis 6.0+ 引入了多线程 I/O,但执行命令的主线程仍是单线程。
4. 什么是缓存预热
缓存预热是指系统启动时,提前将热点数据加载到缓存中,避免用户请求直接打到数据库。
实现方式:
- 编写脚本在应用启动时加载热点数据
- 定时任务刷新热点数据
- 用户请求时懒加载 + 异步刷新
5. 如何解决 Redis 缓存雪崩
缓存雪崩是指大量缓存同时失效或缓存服务宕机,导致所有请求直接打到数据库。
解决方案:
- 过期时间打散:在基础过期时间上增加随机值
- 缓存服务高可用:Redis 主从 + Sentinel 或 Cluster
- 服务降级与熔断:使用 Hystrix/Sentinel 保护数据库
- 永不过期:热点数据不设置过期时间,后台异步更新
6. 布隆过滤器原理与应用
原理:
- 利用位数组和多个哈希函数
- 元素通过多个哈希函数映射到位数组的多个位置
- 判存时检查所有映射位置是否都为 1
特点:
- 可能误判(说存在可能不存在),但不会漏判(说不存在一定不存在)
- 不能删除元素(Counting Bloom Filter 支持)
应用场景:
- 缓存穿透防护
- 垃圾邮件过滤
- URL 去重
1 | // Guava BloomFilter 示例 |
7. Redis 事务原理
Redis 事务通过 MULTI、EXEC、DISCARD、WATCH 四个命令实现:
1 | MULTI # 开启事务 |
特点:
- 批量操作送入队列,EXEC 时原子执行
- 不支持回滚(某条命令失败,后续仍会执行)
- WATCH 可实现乐观锁:监视的 key 被修改则事务中止
8. 分布式锁实现
方案一:SETNX + EXPIRE(有竞态问题)
1 | SETNX lock 1 |
方案二:SET 原子命令(推荐)
1 | SET lock uuid NX PX 30000 # 同时设置值和过期时间 |
方案三:Redisson(生产环境常用)
1 | RLock lock = redisson.getLock("myLock"); |
9. Redis 实现消息队列
方案一:List + LPUSH / BRPOP
1 | LPUSH queue msg1 msg2 |
方案二:Pub/Sub(发布订阅)
1 | SUBSCRIBE channel |
方案三:Stream(5.0+,推荐)
1 | XADD stream * name foo age 20 # 追加消息 |
10. Redis 大 Key 问题
什么是大 Key:
- String 类型 value 超过 10KB
- List/Hash/Set/ZSet 元素数量超过 5000
危害:
- 内存分布不均
- 网络阻塞
- 超时
- 删除时阻塞主线程
解决方案:
- 拆分:将大 Key 拆分为多个小 Key
- 逐步删除:使用 UNLINK(非阻塞删除)代替 DEL
- 监控:定期使用
--bigkeys或--memkeys扫描
1 | redis-cli --bigkeys |
11. Redis 热 Key 问题
热 Key: 某个 Key 被高频访问,导致该 Key 所在节点负载过高。
解决方案:
- 本地缓存:应用层使用 Caffeine/Guava Cache 缓存热点数据
- Key 分片:将热 Key 复制到多个 Key,分散压力
- 集群负载均衡:确保热 Key 分散在不同节点
12. 如何实现 Redis 限流
方案一:基于 ZSet 的滑动窗口
1 | local key = KEYS[1] |
方案二:令牌桶 / 漏桶算法
方案三:Redis-Cell(4.0+ 模块)
1 | CL.THROTTLE user123 15 30 60 1 |
Redis 性能优化建议
键值设计
- Key 名简洁明了,控制在 39 字节内(embstr 编码)
- 避免 Big Key,合理拆分
- 统一命名规范,如
业务:模块:id
内存优化
- 使用 ziplist 等紧凑编码(注意配置
hash-max-ziplist-entries等) - 合理设置过期时间
- 使用对象共享池(整数对象)
- 开启内存淘汰策略
使用建议
- 避免使用 KEYS *,使用 SCAN 代替
- 尽量使用批量命令(MGET、MSET、HMSET)
- 合理使用 Pipeline
- Lua 脚本控制原子性,但避免脚本过长
- 慢查询监控:
SLOWLOG GET 10








